Mở trình duyệt, gõ google.com, nhấn Enter. Chỉ trong tích tắc, trang tìm kiếm quen thuộc hiện ra. Quá trình này nhanh đến mức nhiều người tin rằng máy tính đã “đi thẳng” vào Google. Nhưng thực tế, phía sau cú nhấn Enter đó là một chuỗi thao tác kỹ thuật phức tạp, được Internet và trình duyệt xử lý thay cho người dùng.
Điều đầu tiên cần làm rõ là: máy tính không hiểu tên website. Những gì con người ghi nhớ như google.com chỉ là một cái tên. Đối với máy tính, mọi kết nối trên Internet đều dựa trên địa chỉ số, hay còn gọi là địa chỉ IP. Vì vậy, khi người dùng nhập một tên miền, trình duyệt không thể kết nối ngay lập tức. Nó phải tìm cách chuyển cái tên đó thành một địa chỉ IP cụ thể.
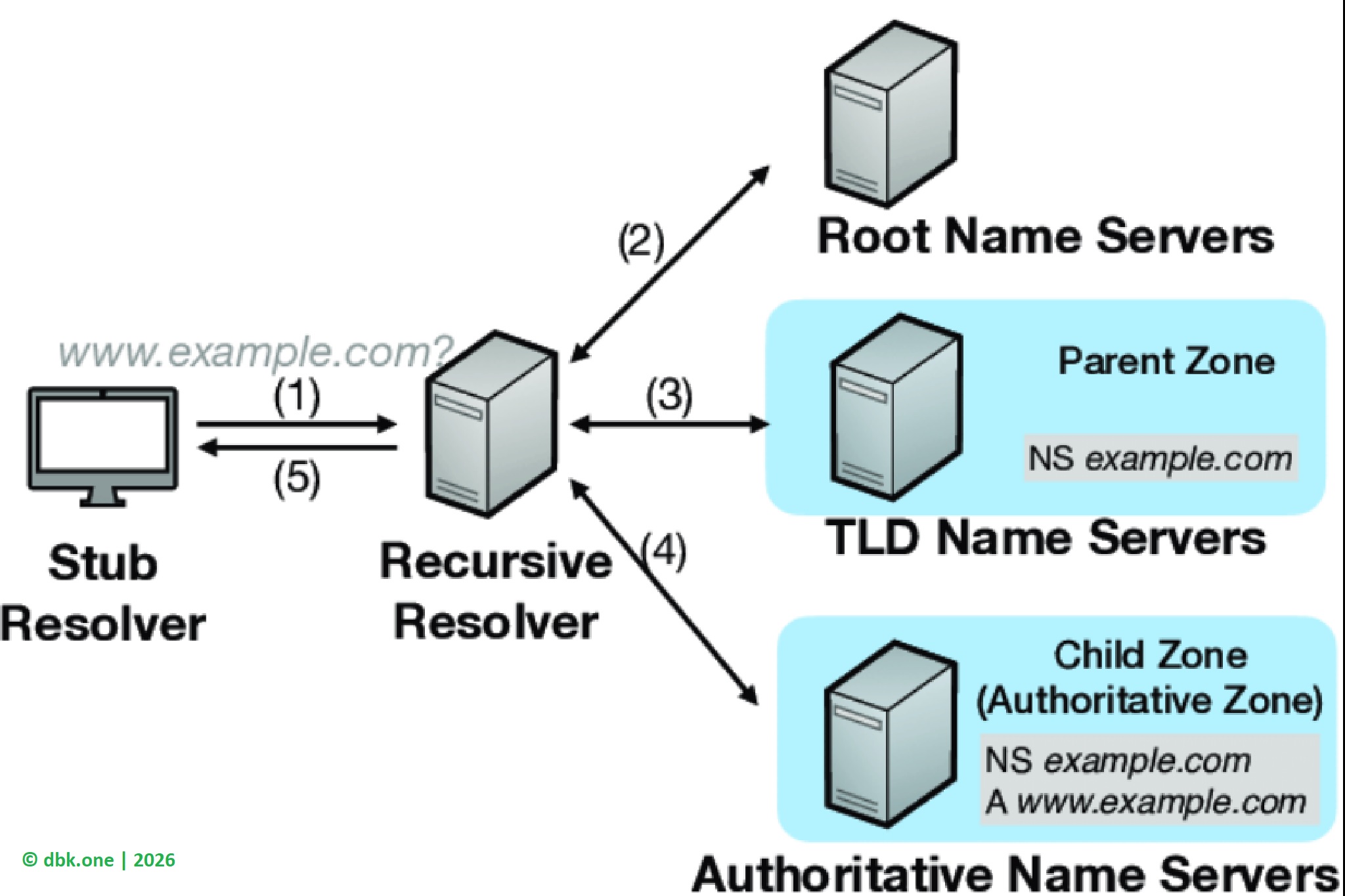
Quá trình “hỏi đường” này được thực hiện thông qua hệ thống DNS – có thể hình dung như danh bạ của Internet. Khi trình duyệt nhận được yêu cầu truy cập google.com, nó trước hết kiểm tra xem địa chỉ này đã từng được lưu lại hay chưa. Nếu không có sẵn, yêu cầu sẽ được gửi tới máy chủ DNS để tra cứu. Chỉ khi DNS trả về địa chỉ IP tương ứng, trình duyệt mới biết chính xác máy chủ nào cần kết nối.
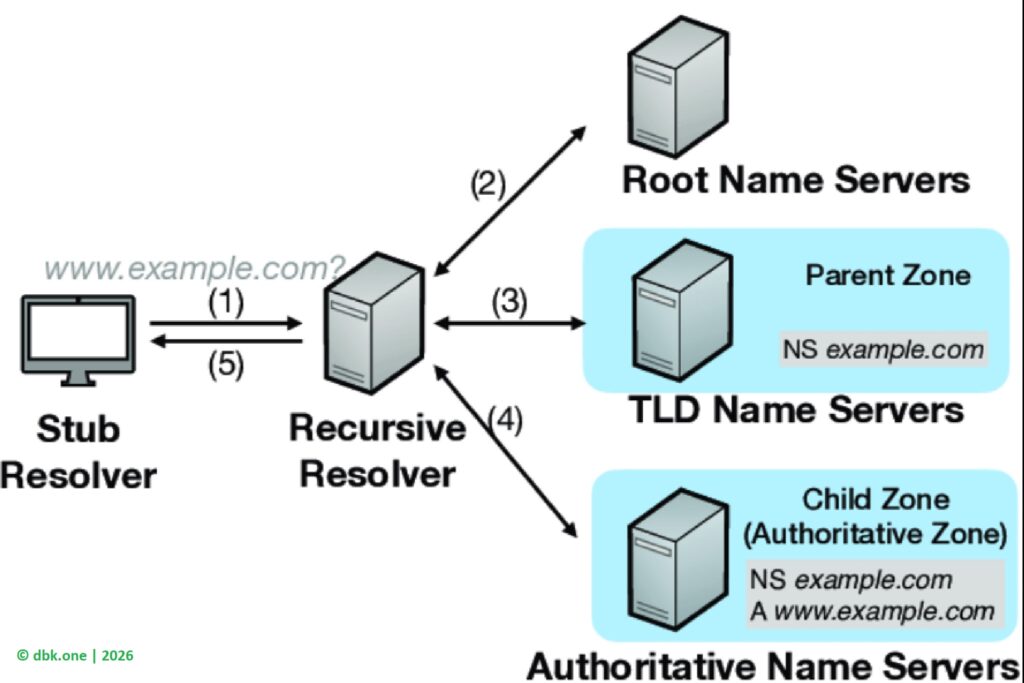
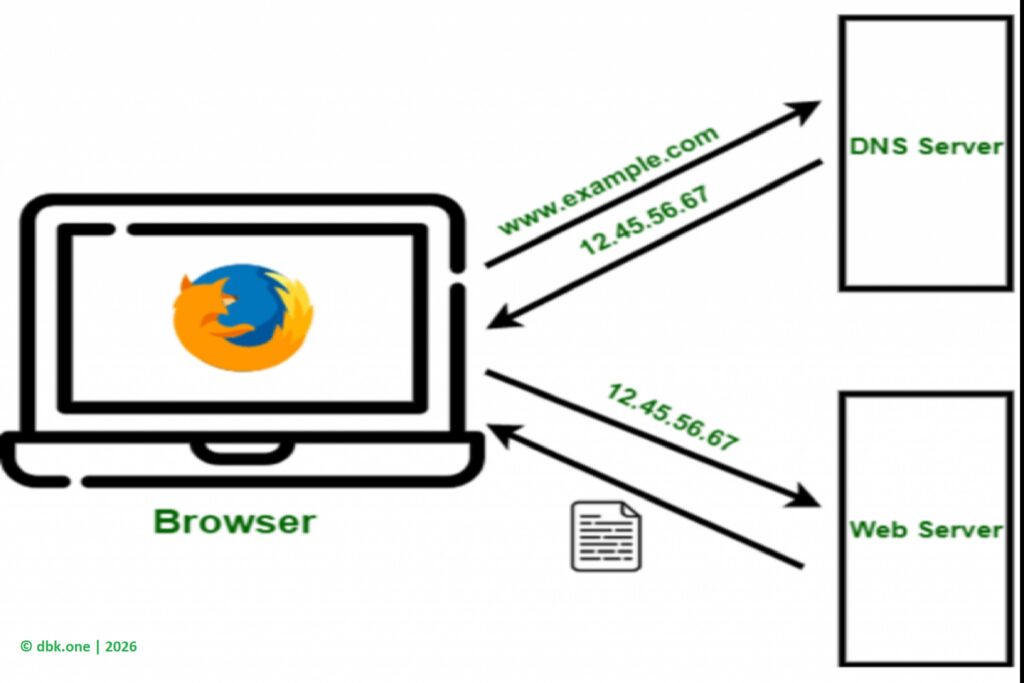
Ở thời điểm này, người dùng vẫn chưa “vào Google”. Trình duyệt mới chỉ xác định được đường đi. Việc tiếp theo là thiết lập kết nối với máy chủ tại địa chỉ IP vừa nhận được. Với các website hiện đại như Google, kết nối này được bảo vệ bằng HTTPS. Điều đó có nghĩa là trình duyệt phải kiểm tra chứng chỉ bảo mật, xác nhận máy chủ là thật và đảm bảo dữ liệu trao đổi không bị nghe lén hay giả mạo.
Chỉ sau khi kết nối an toàn được thiết lập, trình duyệt mới gửi yêu cầu chính thức tới máy chủ. Yêu cầu này về bản chất rất đơn giản: trình duyệt thông báo rằng người dùng muốn xem trang chủ. Kèm theo đó là một số thông tin kỹ thuật như loại trình duyệt, hệ điều hành hay ngôn ngữ hiển thị.
Nhiều người cho rằng từ thời điểm này, máy chủ sẽ gửi “toàn bộ website” về máy tính. Thực tế lại khác. Máy chủ không gửi một trang web hoàn chỉnh như một bức ảnh chụp sẵn. Thứ được gửi về thường chỉ là một tệp HTML – đóng vai trò như khung xương của trang – cùng với các chỉ dẫn để trình duyệt tải thêm các thành phần khác.
Những thành phần đó bao gồm CSS, dùng để định dạng giao diện, và JavaScript, dùng để xử lý các tương tác. Nói cách khác, máy chủ chỉ cung cấp nguyên liệu, còn việc “xây dựng” trang web là trách nhiệm của trình duyệt.
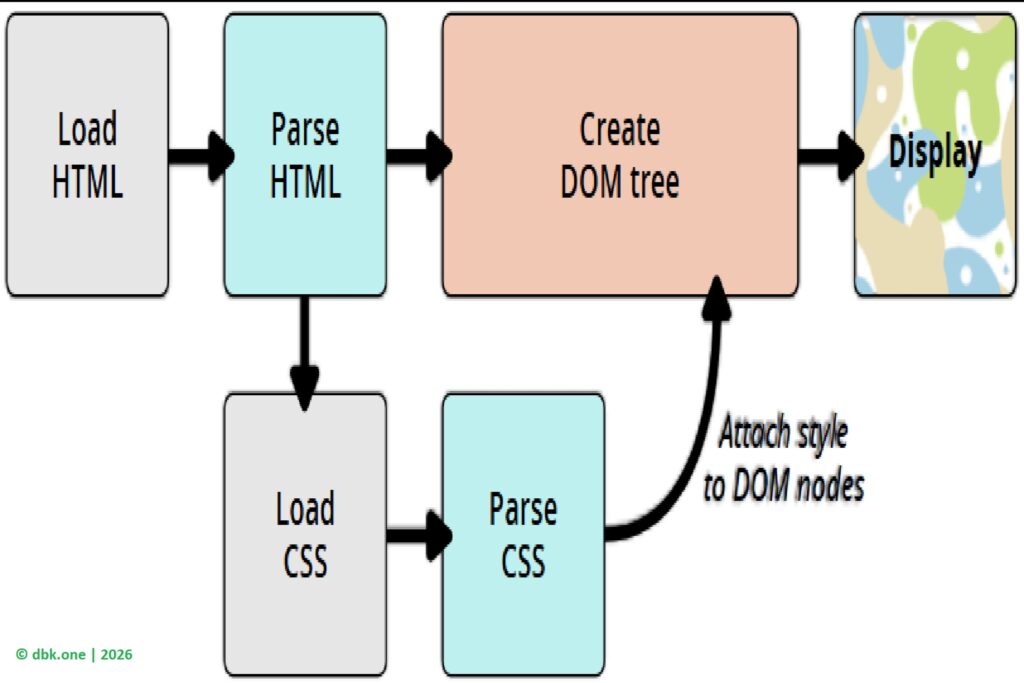

Khi nhận được dữ liệu, trình duyệt bắt đầu đọc cấu trúc nội dung, tải các tệp cần thiết, thực thi mã JavaScript và từng bước dựng giao diện. Website mà người dùng nhìn thấy trên màn hình là kết quả của quá trình này. Chính vì vậy, cùng một website có thể hiển thị khác nhau trên các trình duyệt khác nhau, hoặc tải nhanh chậm tùy vào thiết bị và điều kiện mạng.
Tất cả những bước trên nghe có vẻ dài dòng, nhưng trên thực tế chỉ diễn ra trong vài chục đến vài trăm mili-giây. DNS thường đã được lưu sẵn, kết nối mạng được tối ưu, và các máy chủ lớn như Google được đặt ở nhiều khu vực khác nhau để rút ngắn khoảng cách tới người dùng. Chính sự tối ưu này tạo ra cảm giác rằng trang web xuất hiện “ngay lập tức”.
Cảm giác đó đôi khi khiến người dùng bối rối khi gặp sự cố. Một trang web không truy cập được có thể không phải vì “Internet bị hỏng”, mà do DNS không phản hồi, kết nối bảo mật gặp vấn đề hoặc trình duyệt không xử lý được dữ liệu nhận về. Khi hiểu được chuỗi quy trình phía sau, việc xác định nguyên nhân sự cố trở nên logic hơn rất nhiều.
Khi nhìn lại toàn bộ quá trình, có thể thấy rằng việc “vào Google” không hề đơn giản như một cú nhấn phím. Người dùng đang kích hoạt một hệ thống gồm nhiều tầng: từ chuyển đổi tên miền, thiết lập kết nối an toàn, gửi yêu cầu, nhận dữ liệu cho tới khâu dựng giao diện trên trình duyệt.
Sự phức tạp này không nhằm làm mọi thứ rối rắm hơn, mà để Internet hoạt động ổn định, an toàn và nhanh chóng cho hàng tỷ người dùng cùng lúc. Và chính vì mọi thứ được che giấu quá tốt, người dùng mới có cảm giác rằng chỉ cần gõ một địa chỉ là đã “đến nơi”.
Hiểu được điều đó giúp ta nhìn Internet thực tế hơn: không thần thánh hóa công nghệ, nhưng cũng đủ trân trọng những hệ thống đang âm thầm vận hành phía sau mỗi lần nhấn Enter.